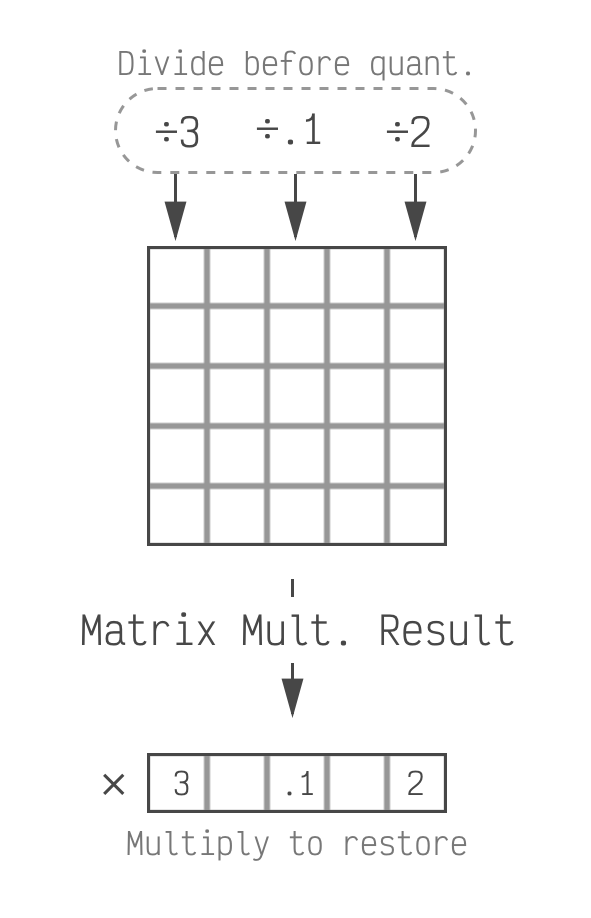
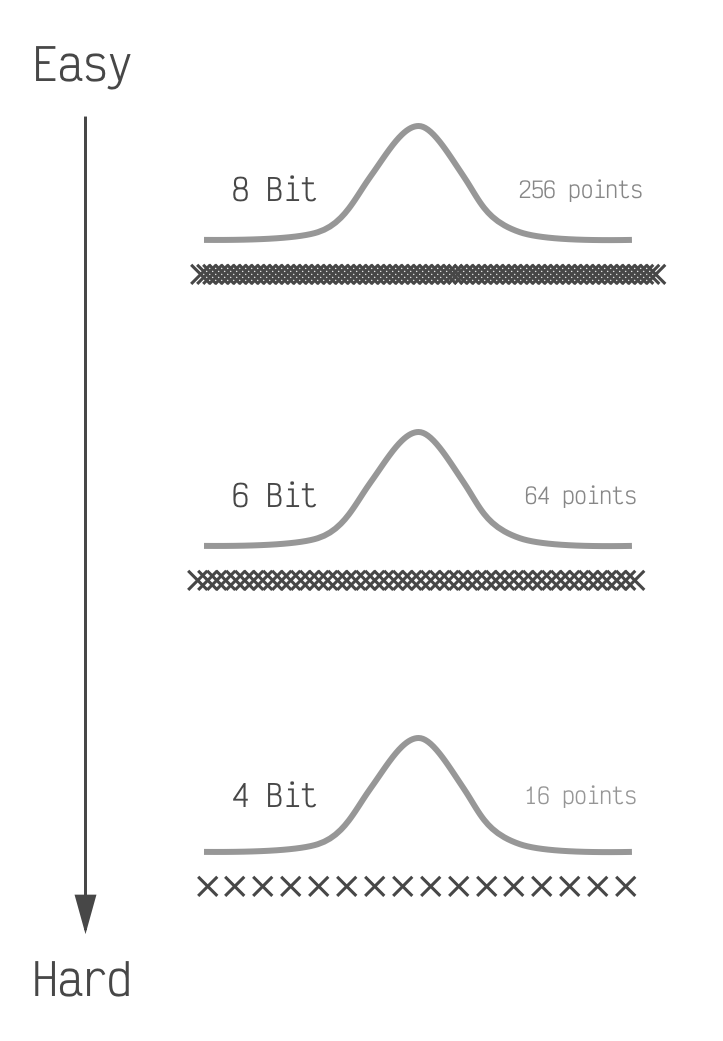
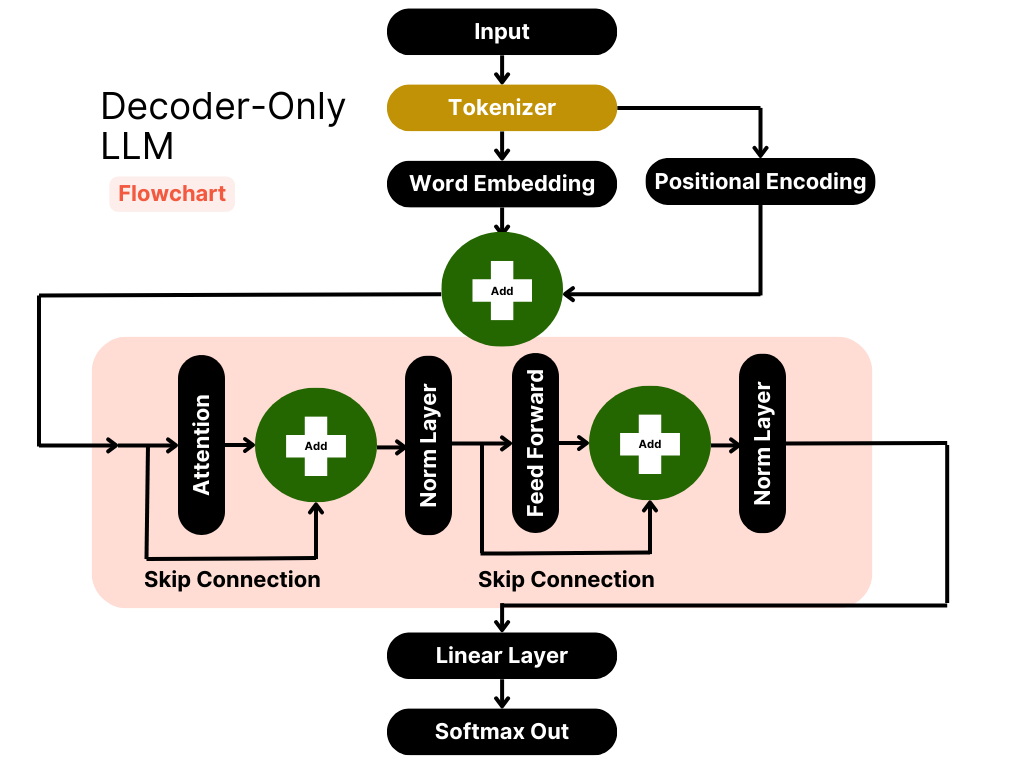
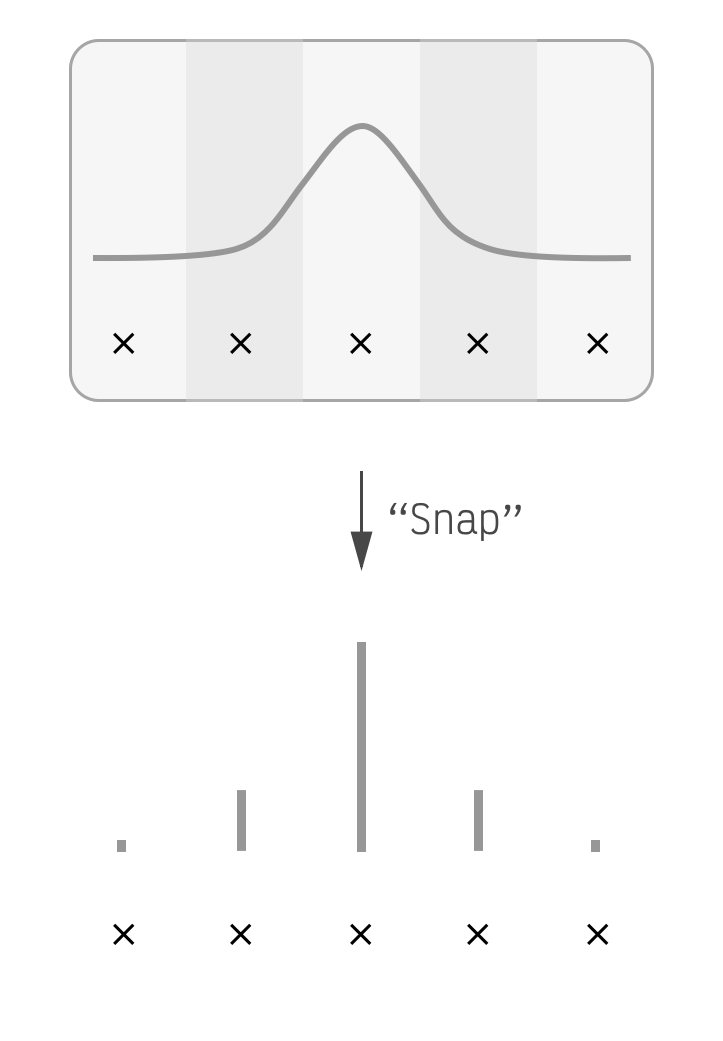
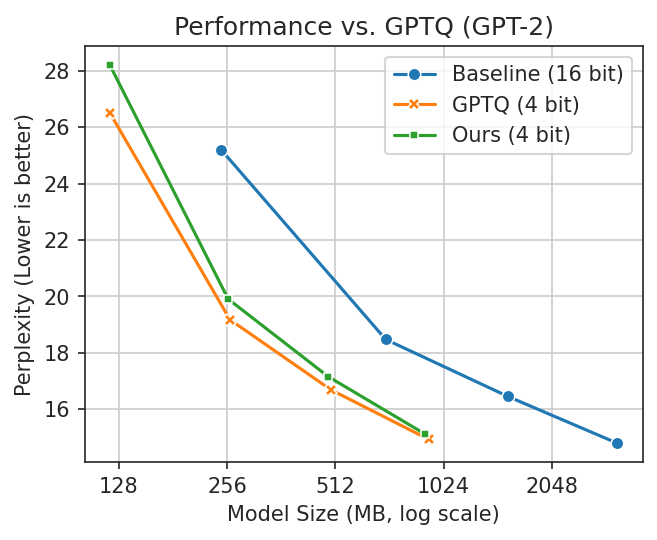
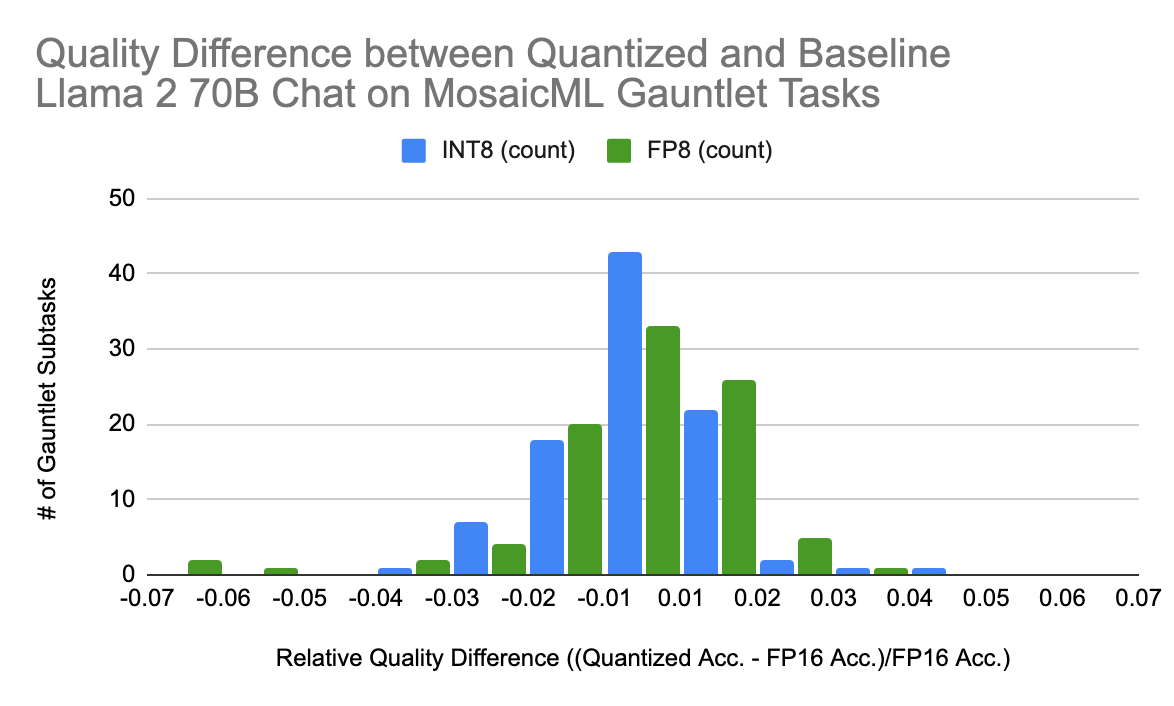
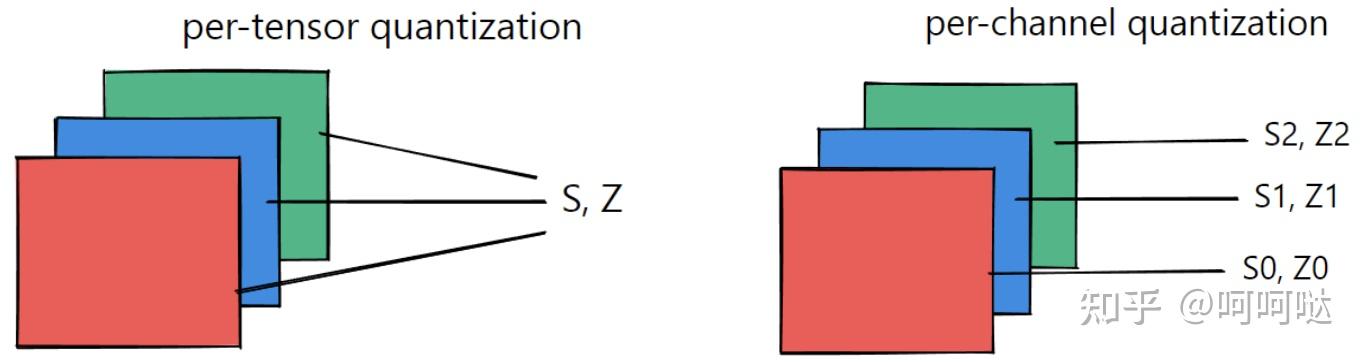
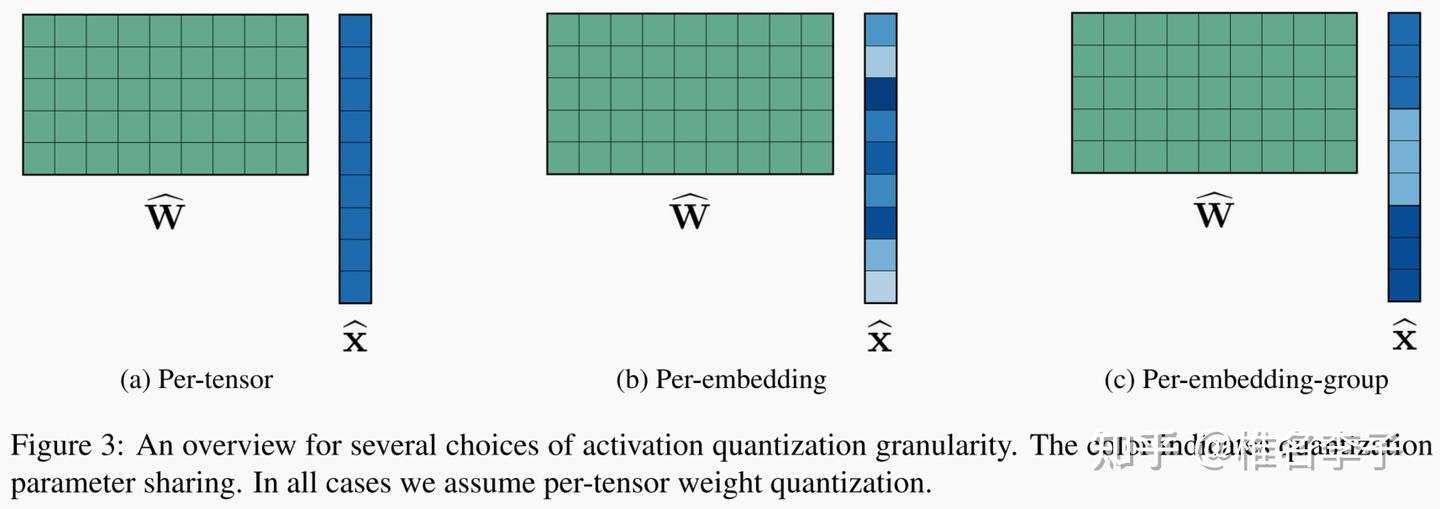
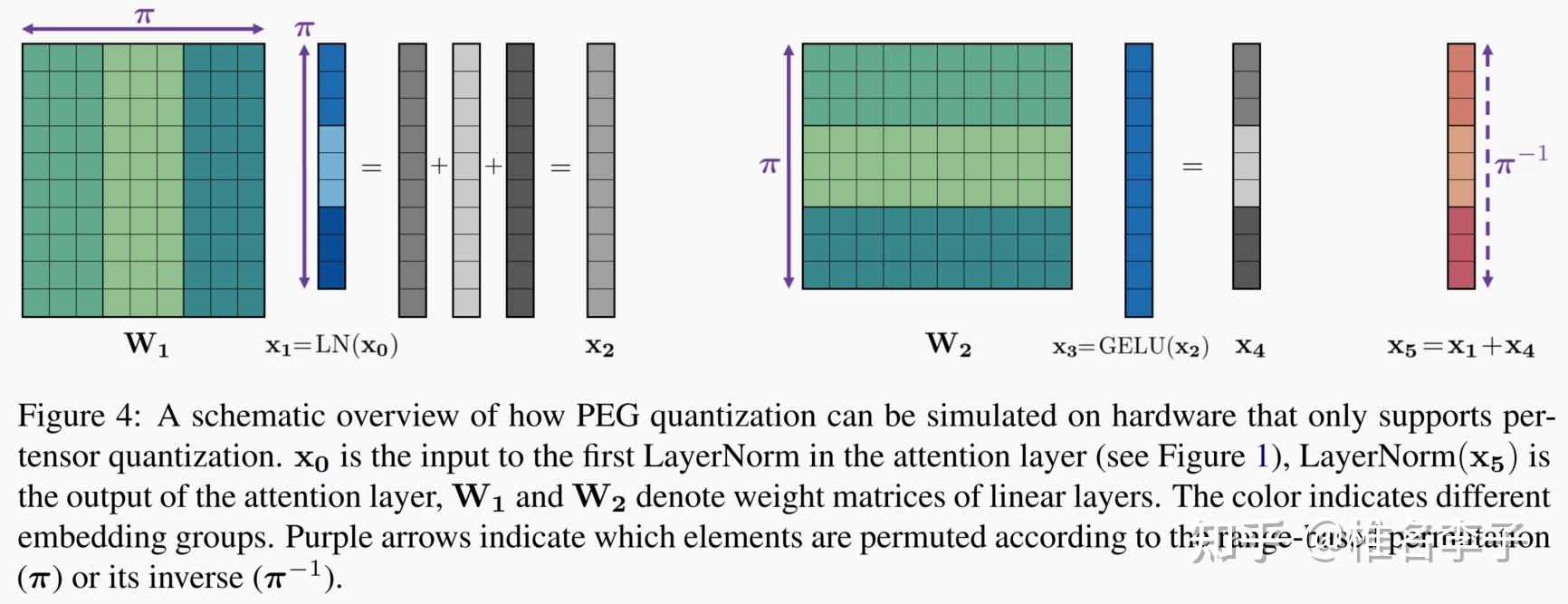
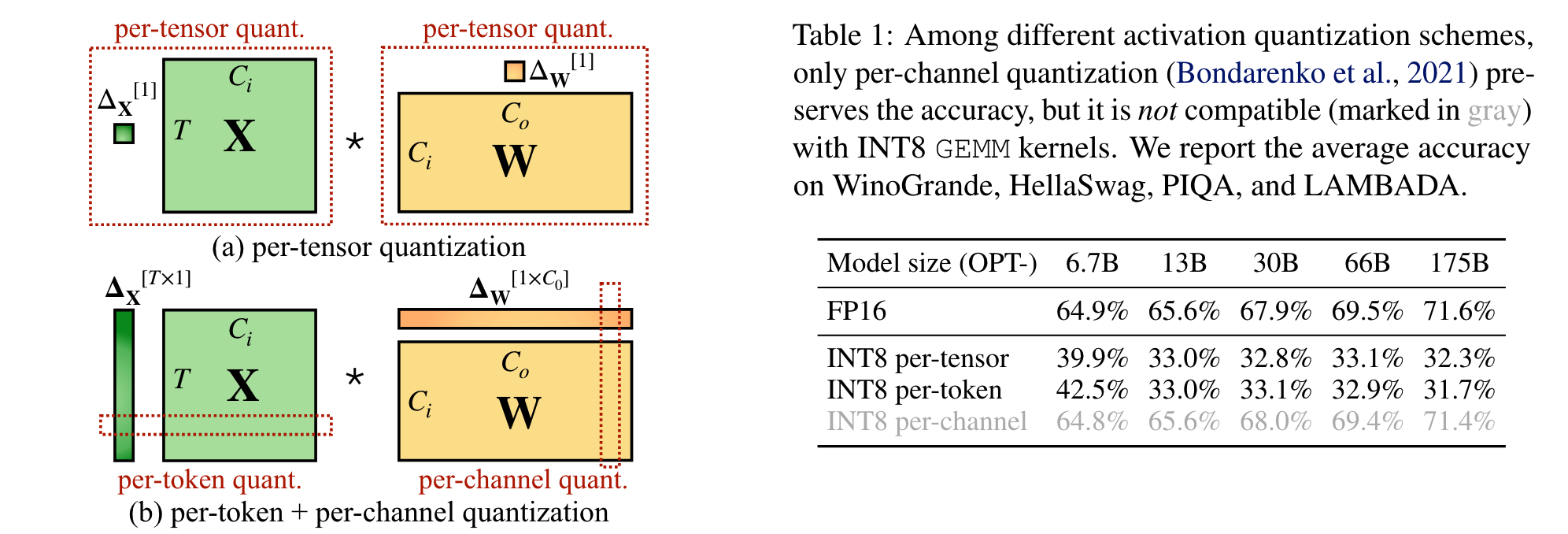
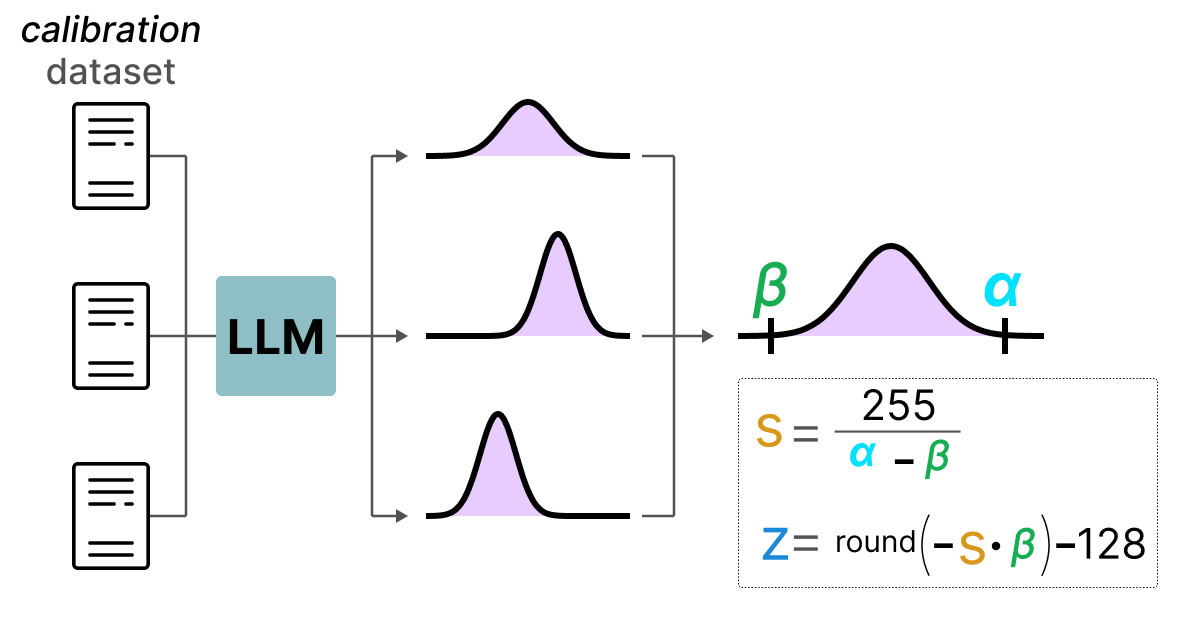
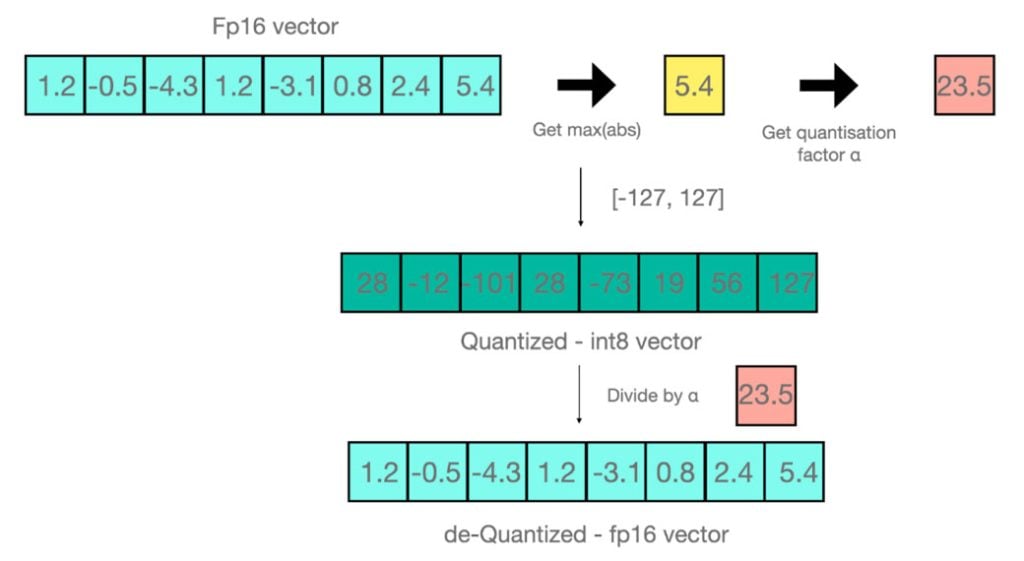
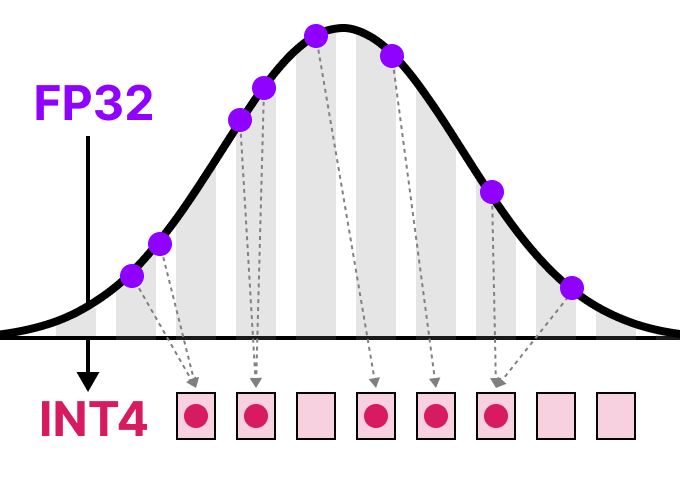
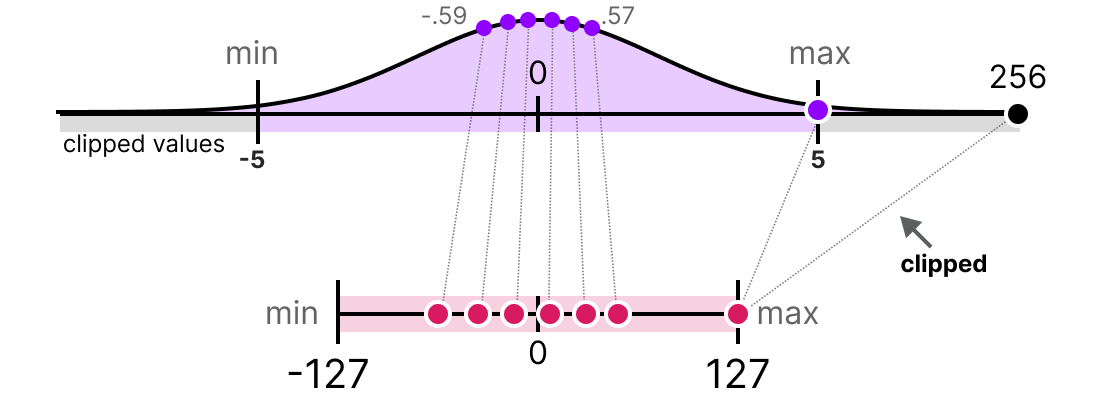
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
Quantum-inspired Tensor Networks for LLM compression: 93% memory ...
The Ultimate Handbook for LLM Quantization | Towards Data Science
Top LLM Quantization Methods and Their Impact on Model Quality
LLM Quantization Made Easy: Essential Tips for Success
An Introduction to LLM Quantization - TextMine
A Comprehensive Guide on LLM Quantization and Use Cases
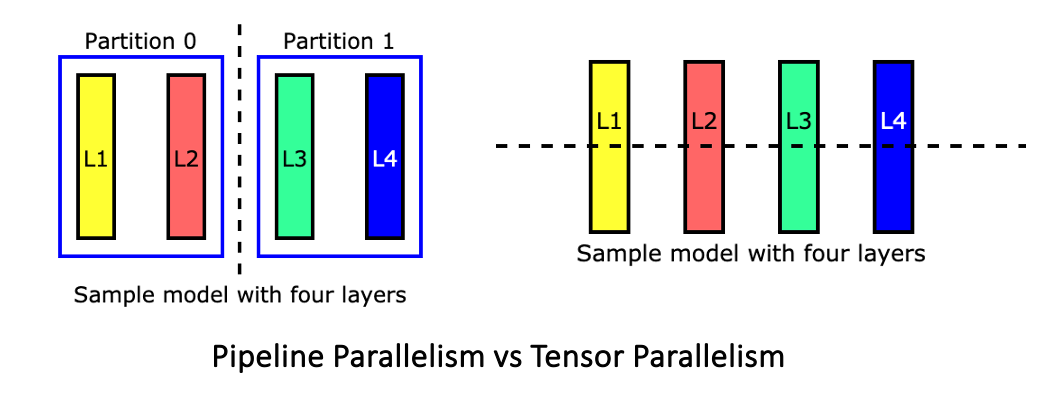
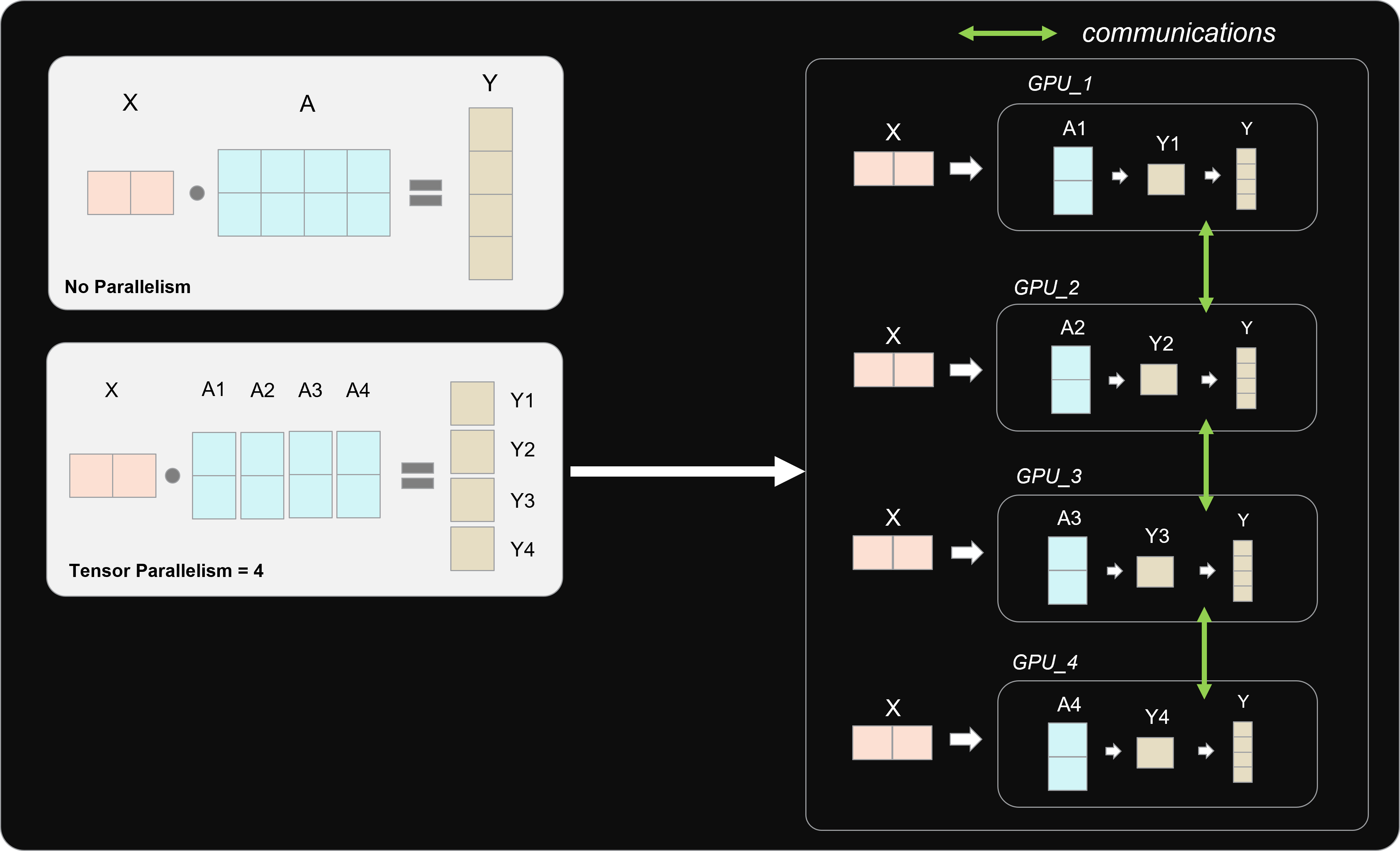
Tensor Parallel LLM Inferencing. As models increase in size, it becomes ...
[논문 리뷰] Lossless Compression for LLM Tensor Incremental Snapshots
SpinQuant -- LLM quantization with learned rotations | AI Research ...
Practical Guide to LLM Quantization Methods - Cast AI
The Complete Guide to LLM Quantization | LocalLLM.in
NVIDIA H200 Tensor Core GPUs and NVIDIA TensorRT-LLM Set MLPerf LLM ...
Optimizing LLM Model using Quantization
5 Essential LLM Quantization Techniques Explained
Quantization | LLM Module
LLM Quantization Explained - YouTube
Improving LLM Inference Latency on CPUs with Model Quantization ...
LLM By Examples — Use GGUF Quantization | by MB20261 | Medium
Simplify LLM Quantization Process for Success | by Novita AI | Jul ...
Overview of LLM Quantization Techniques & Where to Learn Each of Them ...
How LLM Quantization Works for Efficient AI Deployment
A Beginner's Guide to LLM Quantization
What is LLM Quantization and How to Use Them?
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
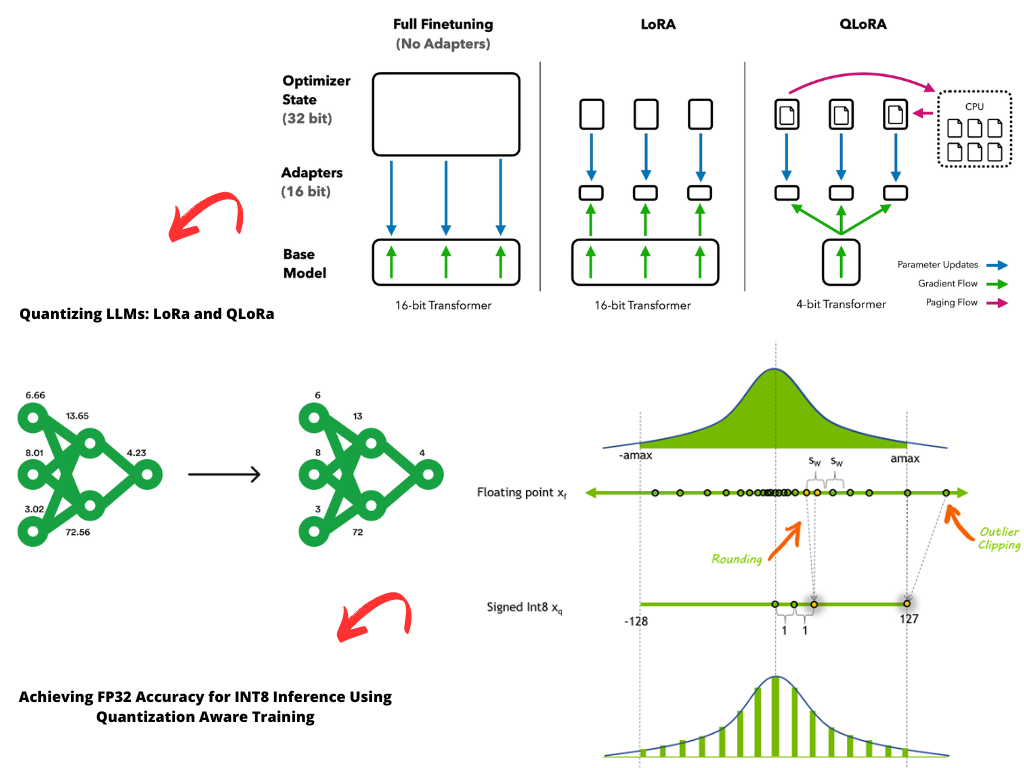
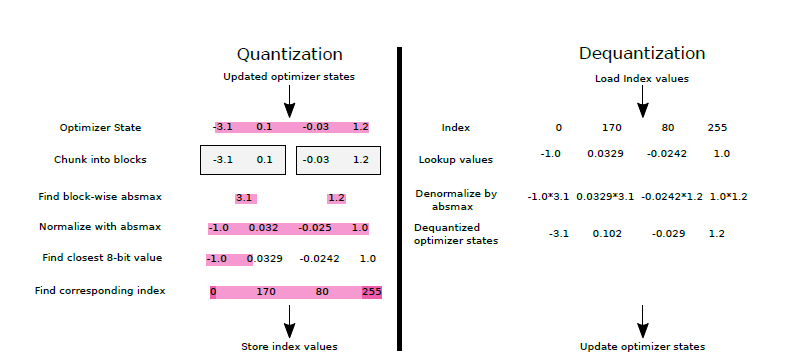
4-bit LLM training and Primer on Precision, data types & Quantization
Quantization Techniques to Reduce LLM Model Size and Memory: A Complete ...
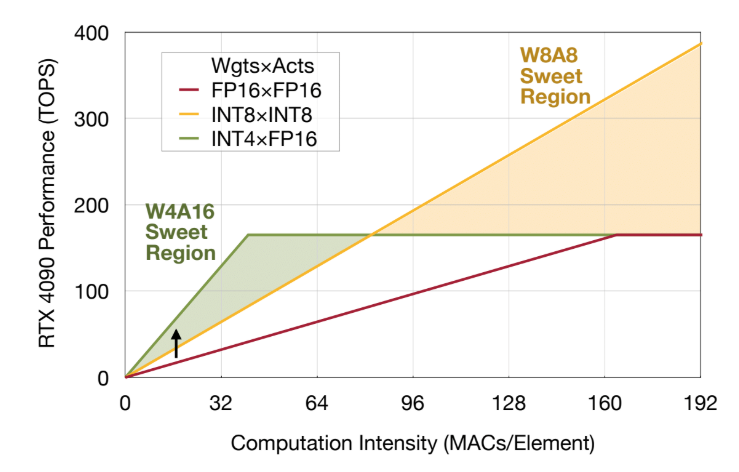
Analyzing the Impact of Tensor Parallelism Configurations on LLM ...
LLM Tutorial 21 — Model Compression Techniques: Quantization, Pruning ...
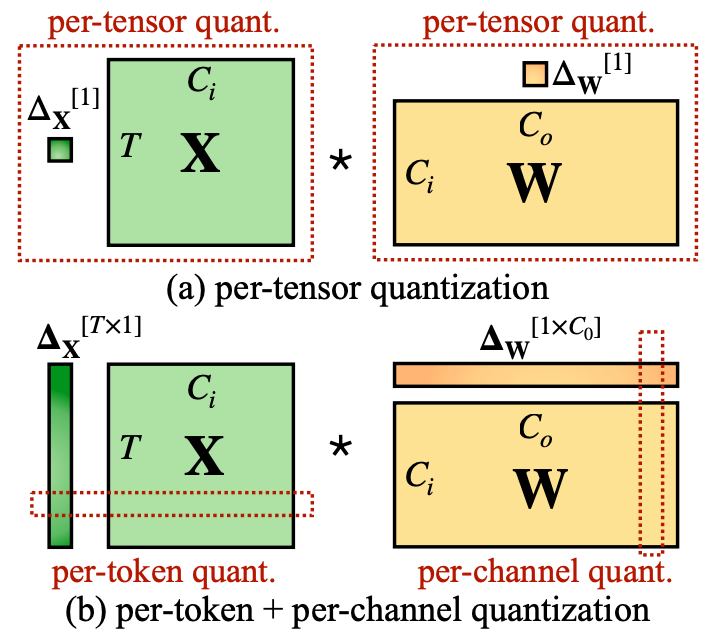
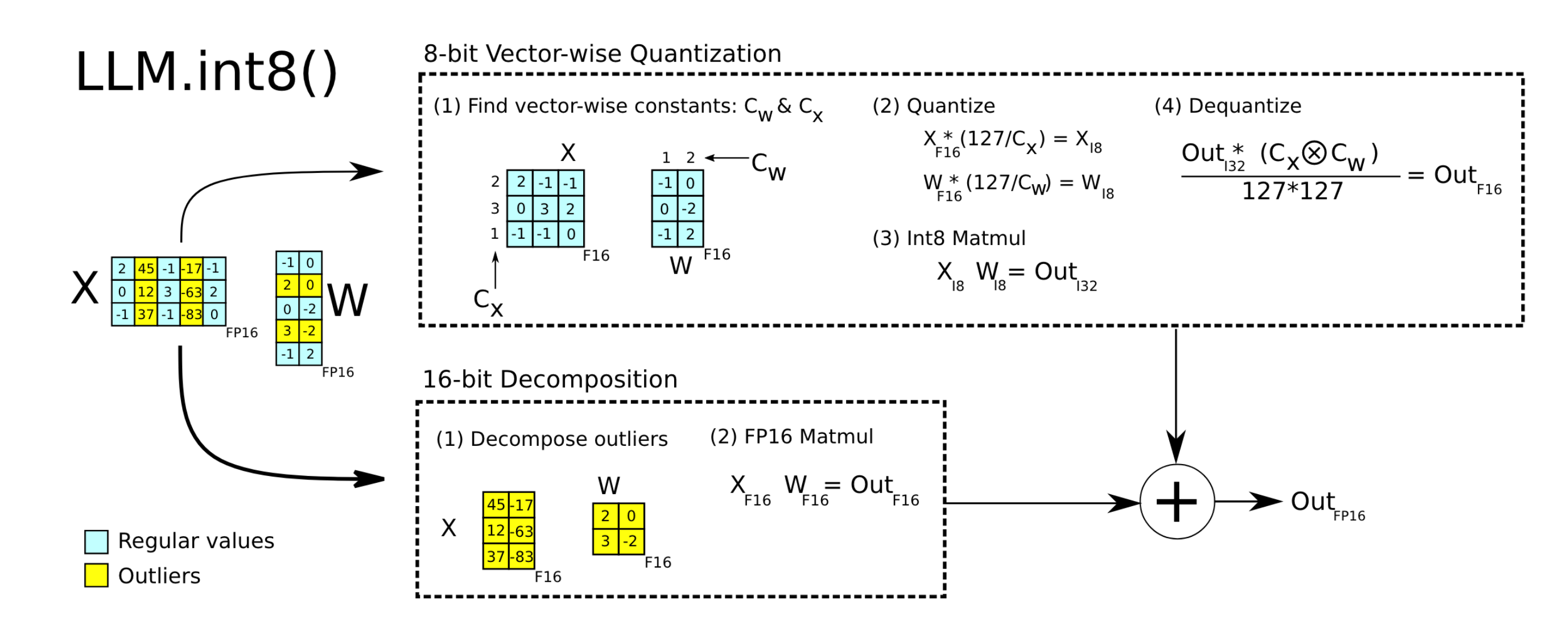
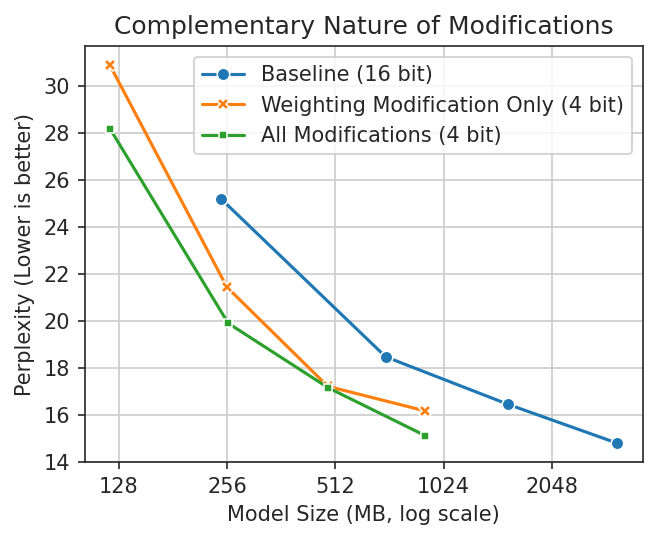
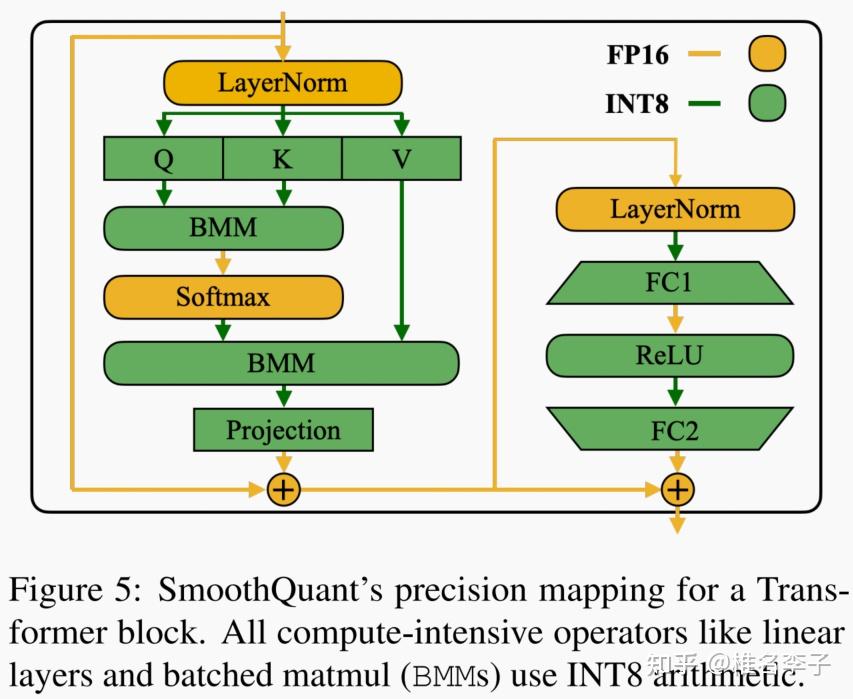
SmoothQuant: Accurate and Efficient Post-Training Quantization for ...
A Survey of LLM Inference Systems | alphaXiv
LLM Quantization-Build and Optimize AI Models Efficiently
What is Quantization in LLM. Large Language Models comes in all… | by ...
Quantization 1/2 - Seunghyun Oh
notion image
Quantization trong LLM: Tối ưu hóa tốc độ Mô hình Ngôn ngữ Lớn - Blog ...
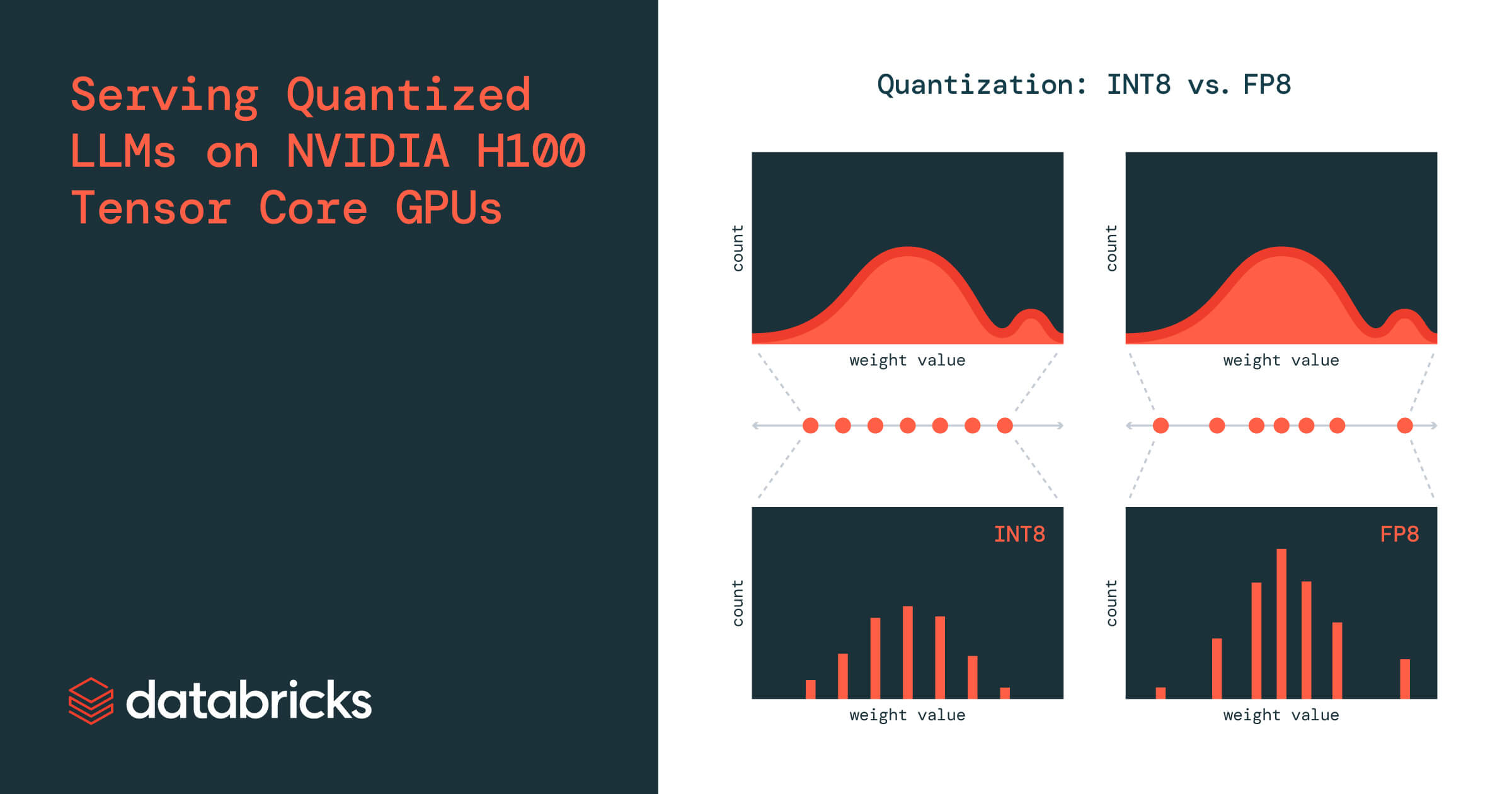
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks Blog
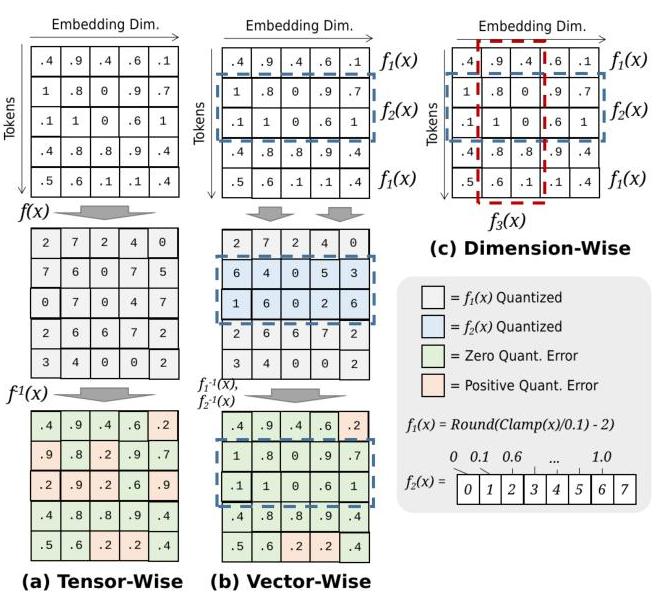
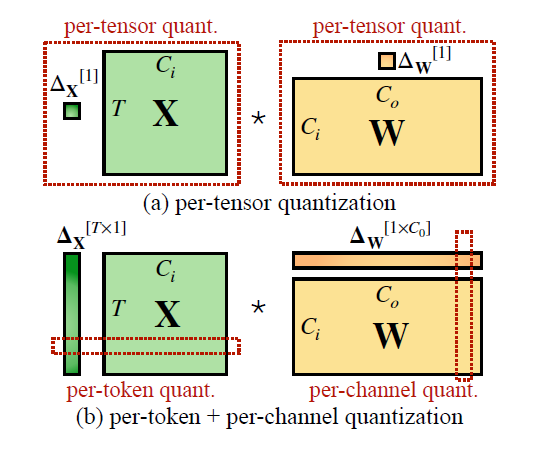
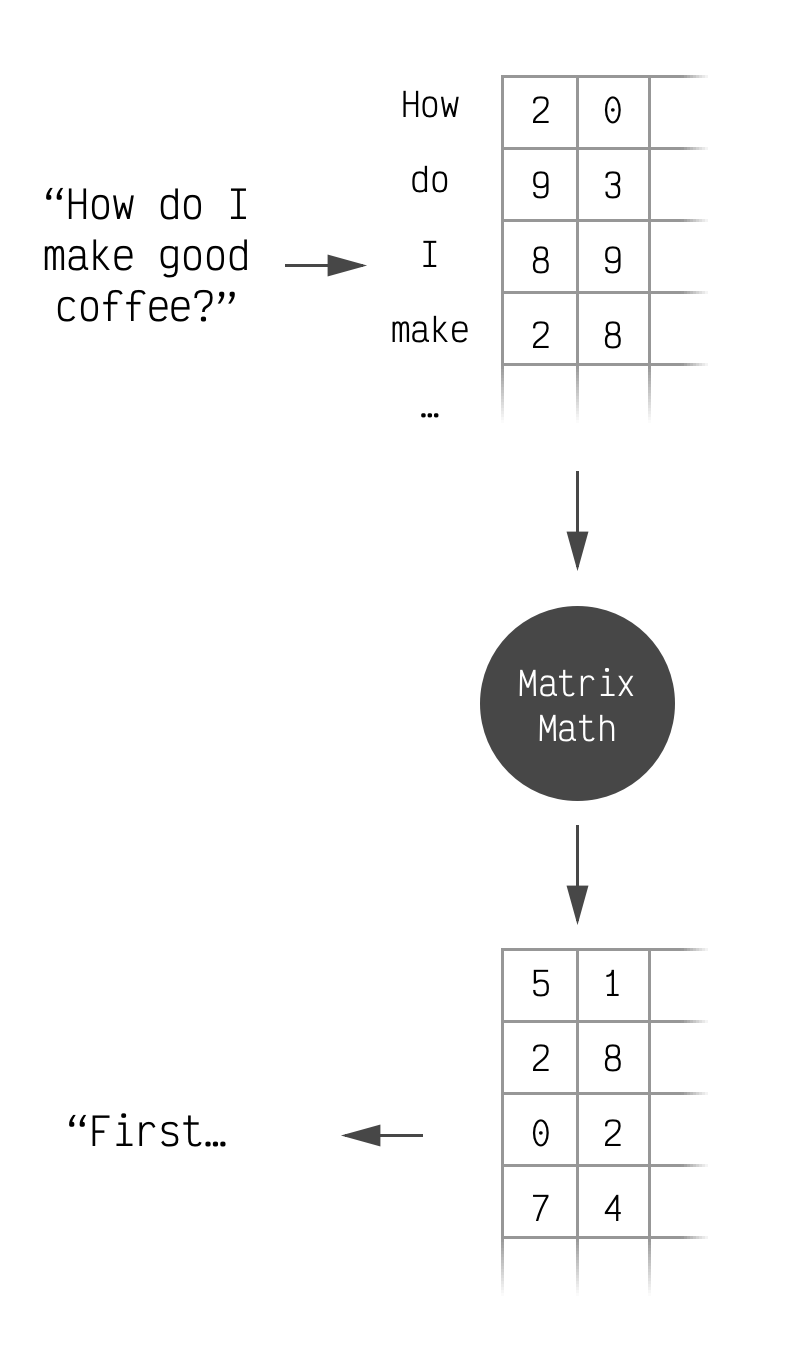
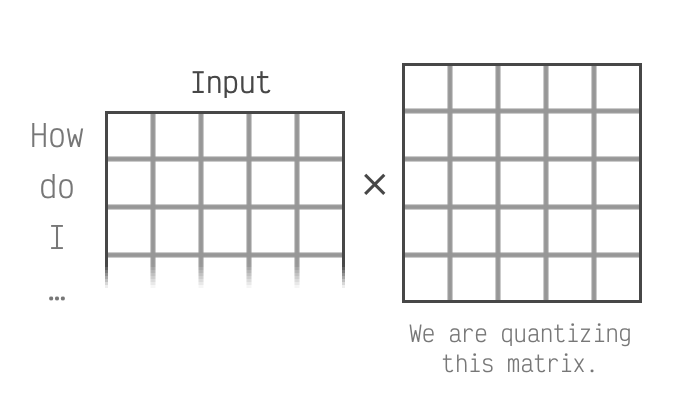
How Quantization Works: From a Matrix Multiplication Perspective ...
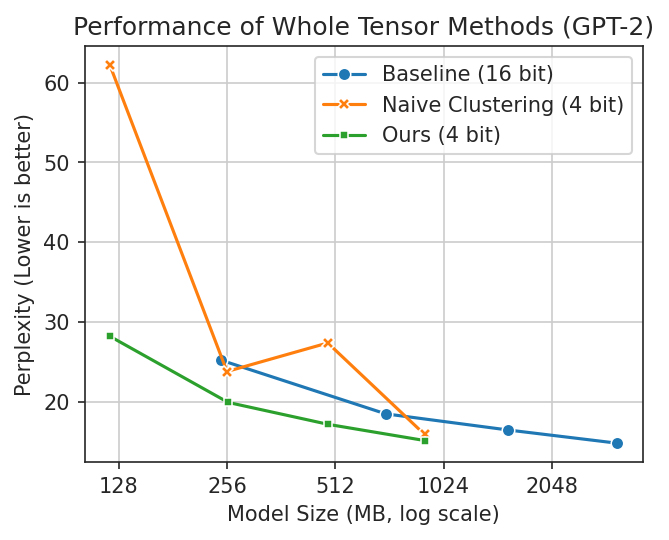
LLMs for your iPhone: Whole-Tensor 4 Bit Quantization
Free Video: LLM Explainability and Controllability Improvements with ...
What is Quantization in LLM? A Complete Guide to Optimizing AI
LLM Quantization: Making models faster and smaller | MatterAI Blog
How to optimize large deep learning models using quantization
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
[vLLM vs TensorRT-LLM] #7. Weight-Activation Quantization - SqueezeBits
LLM 量化技术小结 - 知乎
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
LLM Compressor 0.9.0: Attention quantization, MXFP4 support, and more ...
Understanding LLM Quantization. With the surge in applications using ...
Understanding Quantization in Large Language Models | by ...
LLM Inference Optimisation — Continuous Batching | by YoHoSo | Medium
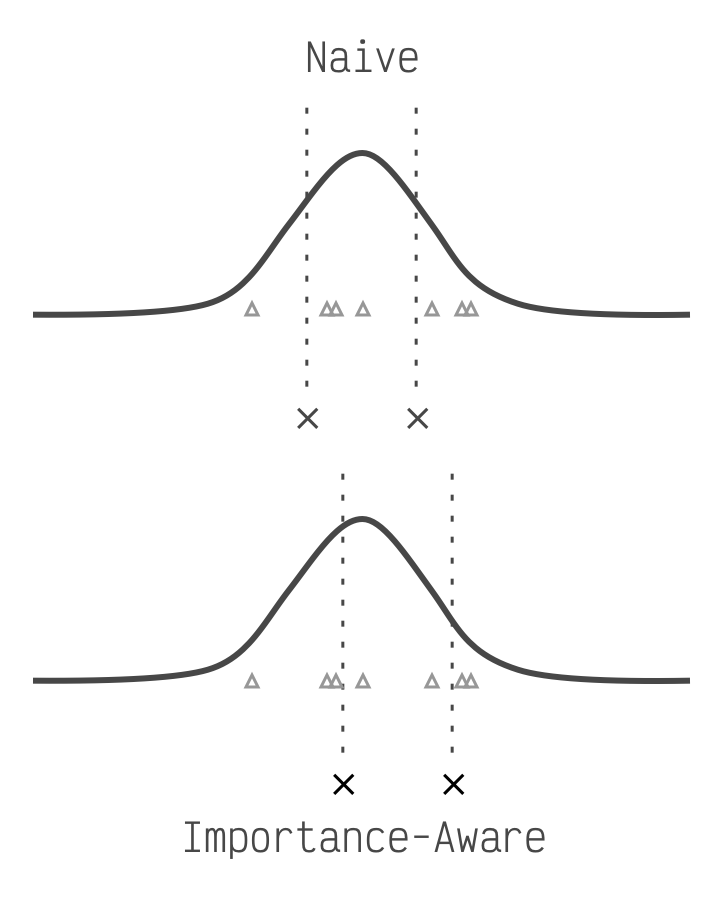
[Paper review] Trained quantization thresholds for accurate and ...
Quantized Tensor Neural Network | ACM/IMS Transactions on Data Science
[vLLM vs TensorRT-LLM] #6. Weight-Only Quantization - AI大模型 - 老潘的AI社区
Understanding Quantization for LLMs | by LM Po | Medium
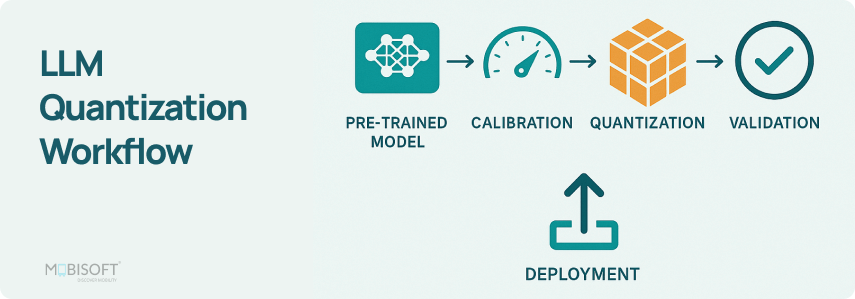
LLM Training Pipeline Overview | AI Tutorial | Next Electronics
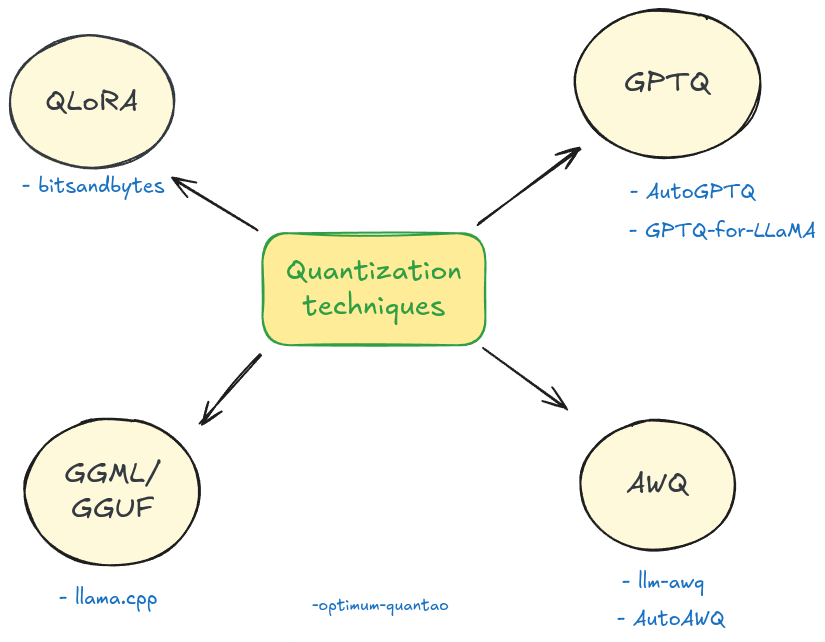
Practical Guide of LLM Quantization: GPTQ, AWQ, BitsandBytes, and ...
NVIDIA H100 Tensor Core GPU上でのクオンタイズ(量子化)LLMの処理 | Databricks Blog
A Guide to Quantization in LLMs | Symbl.ai
LLM Quantization: Quantize Model with GPTQ, AWQ, and Bitsandbytes ...
从0开始实现LLM:6、模型量化理论+代码实战(LLM-QAT/GPTQ/BitNet 1.58Bits/OneBit) - 知乎
MIT-TinyML学习笔记【5】Quantization2 - 知乎
模型量化-llm量化 - 知乎
使用TensorRT LLM的量化实践_tensorrt-llm量化-CSDN博客
Optimizing Inference on Large Language Models with NVIDIA TensorRT-LLM ...
Optimizing LLMs for Performance and Accuracy with Post-Training ...
NVIDIA新推出的Tensor-LLM在优化大语言模型推理上有何突出之处?有大神可以分享一下吗? - 知乎
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
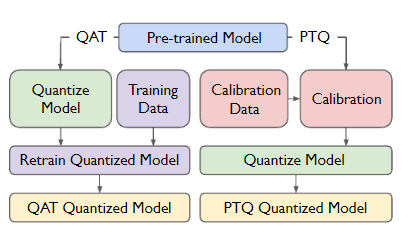
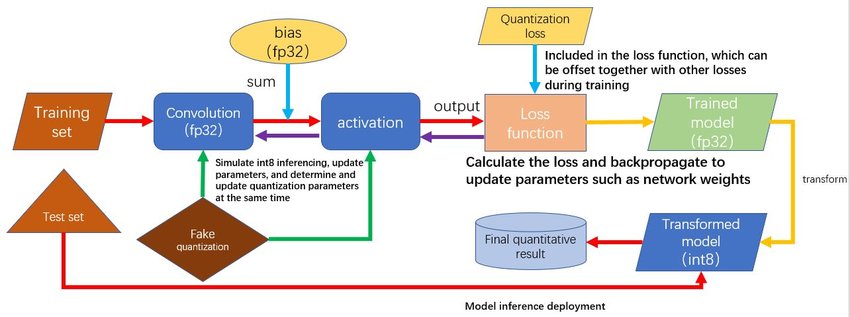
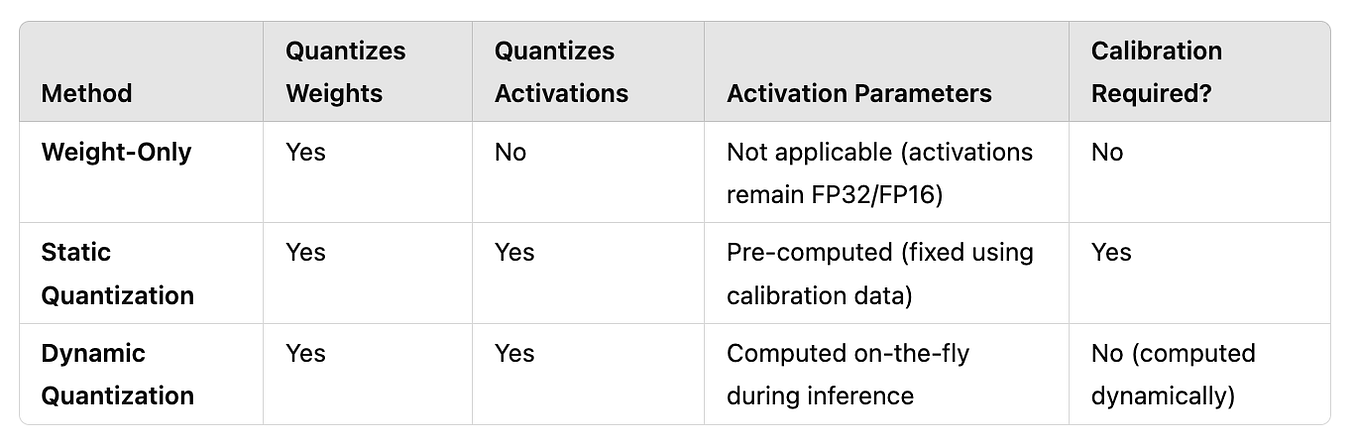
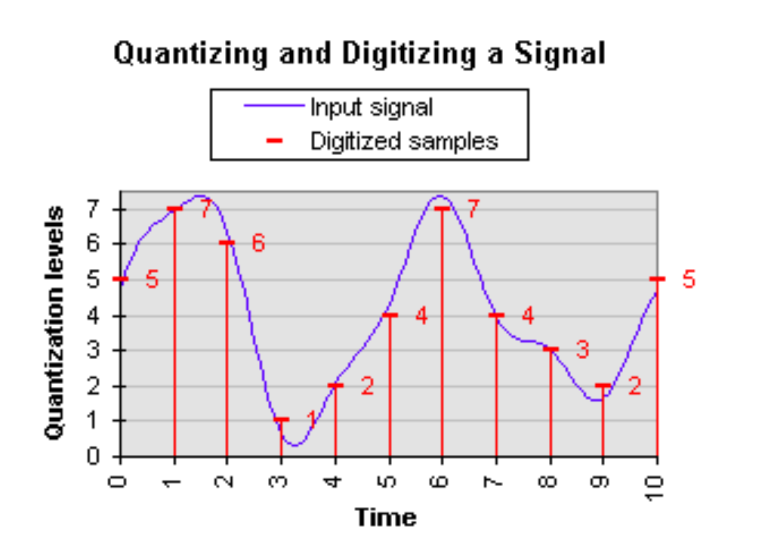
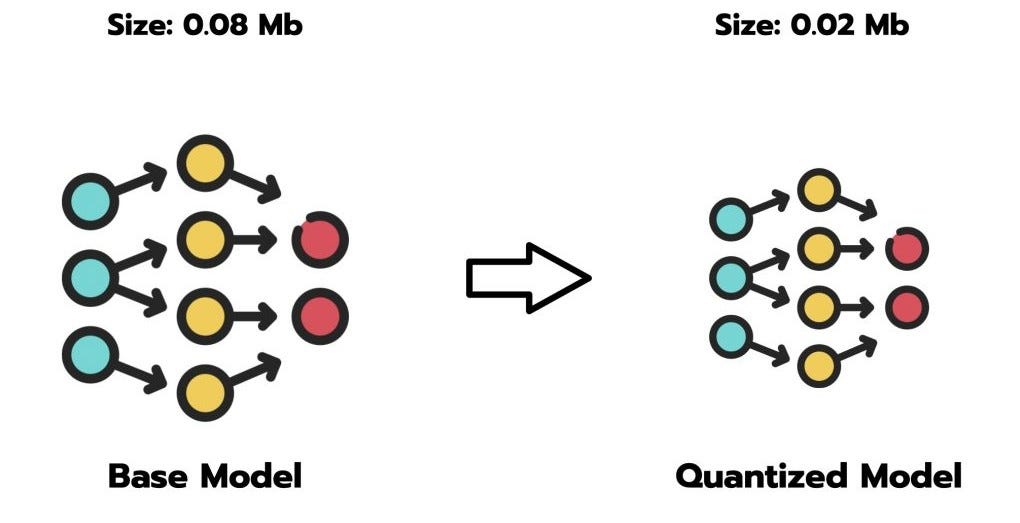
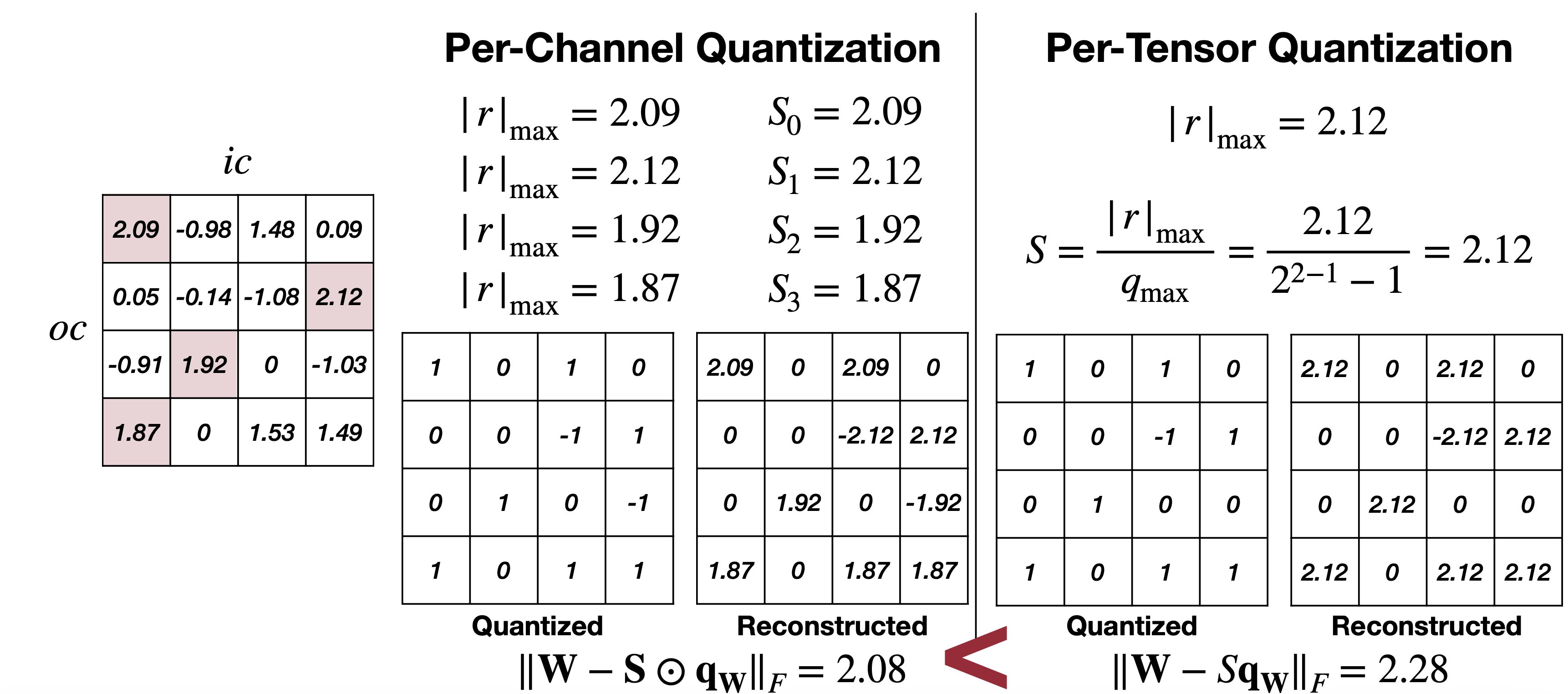
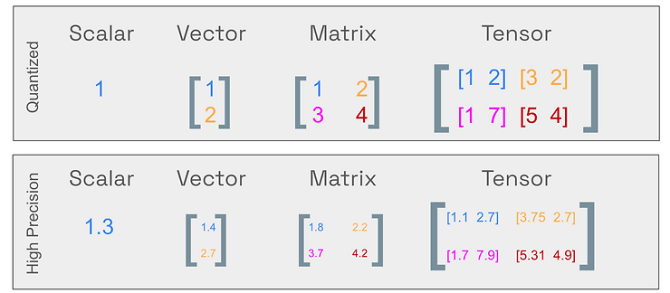
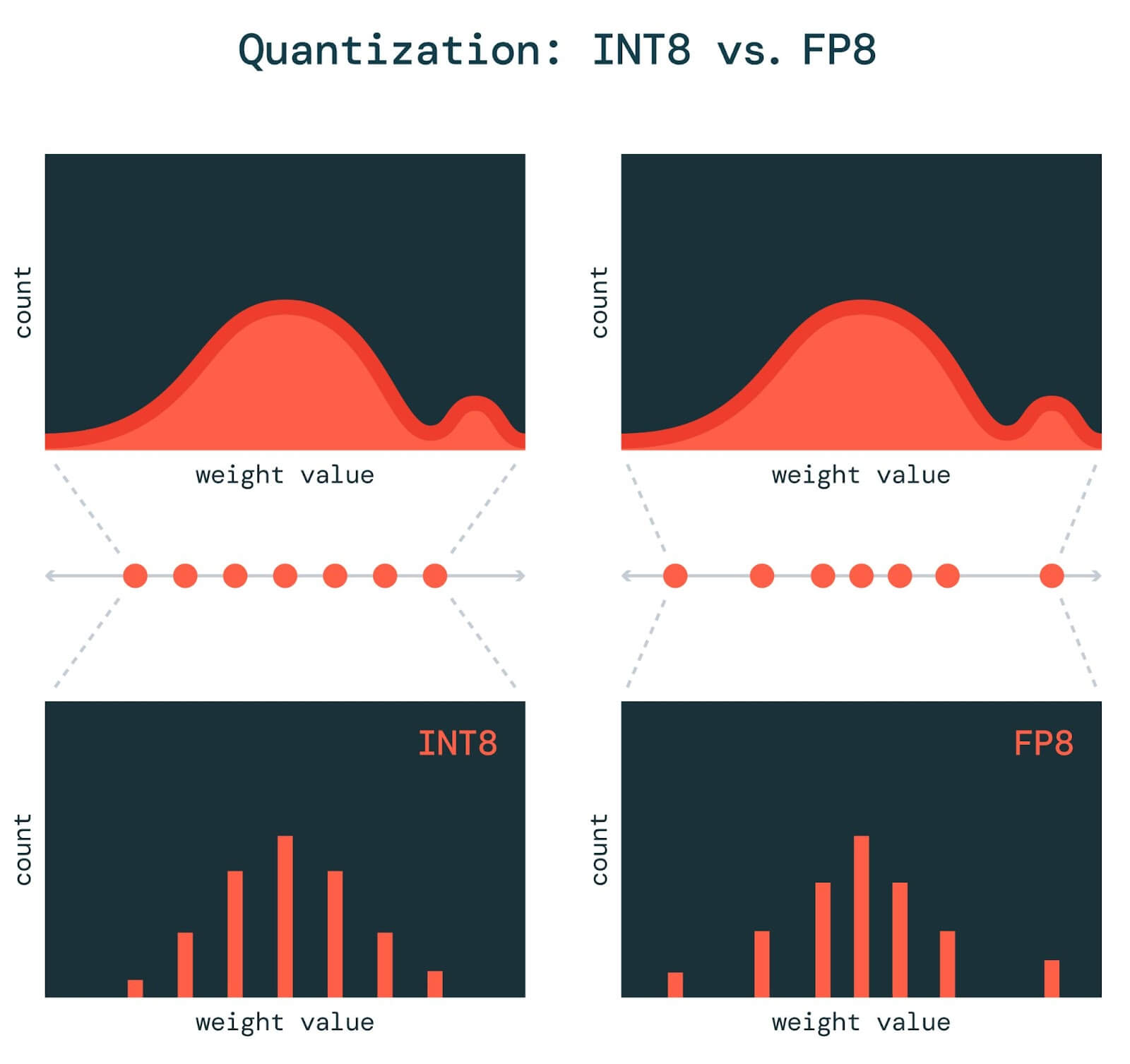
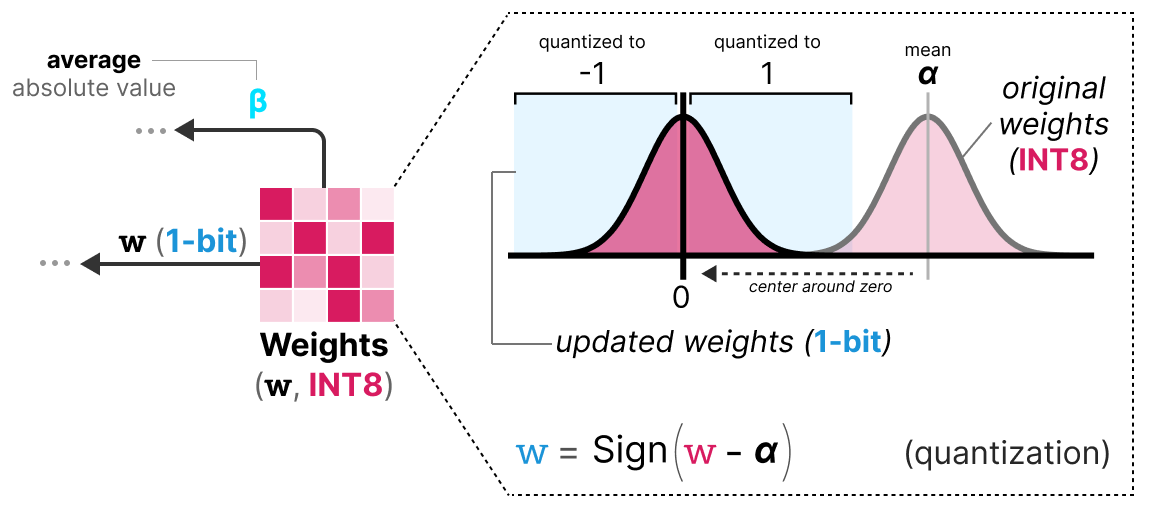
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
Maximizing Business Potential with Large Language Models (LLMs)
What are Quantized LLMs?
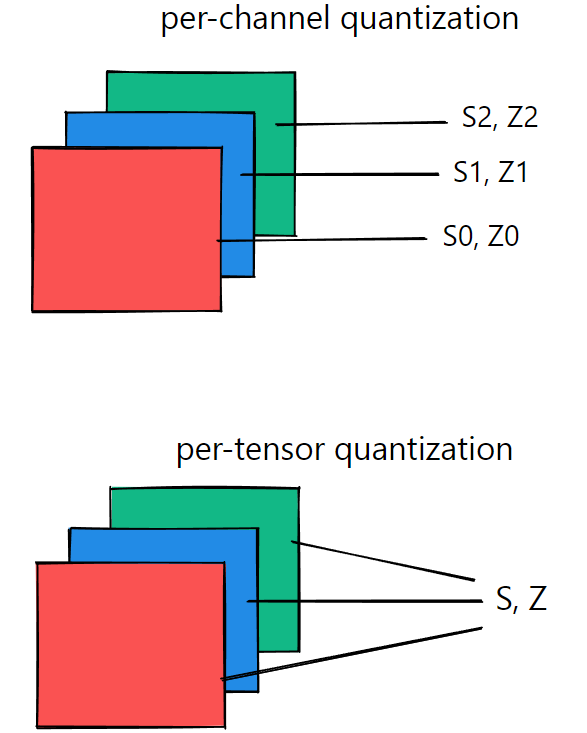
四. TensorRT模型部署优化-quantization(quantization granularity)_tensorrt ...
How to run LLMs on CPU-based systems | UnfoldAI
Analytics Vidhya | Data Science Community | 🚀 Day 31 of Mastering LLMs ...
TensorRT-LLM-Quantization/quant.ipynb at main · CactusQ/TensorRT-LLM ...
LLM论文阅读 | Sekyoro的博客小屋
NVIDIA TensorRT-LLM Revs Up Inference for Google Gemma | NVIDIA ...
TensorRT SDK | NVIDIA Developer